М.А. Перепелкин1, В.В. Курбатова1, В.И. Склянов2, В.В. Тютюнин3, М.В. Козлов4 1 ФГБОУ ВО «Северо-Восточный государственный университет, г. Магадан, Российская Федерация 2 ФГБОУ ВО «Норильский государственный индустриальный институт», г. Норильск, Российская Федерация 3 ООО «Инжи Инжиниринг», г. Иркутск, Российская Федерация 4 АО «Калининградский янтарный комбинат», п. Янтарный, Калининградская область, Российская Федерация Горная Промышленность №2 / 2020 стр. 121-124
Резюме: В настоящее время уровень развития технологий обогащения янтаря требует комплексного анализа существующих методов и средств с фокусировкой на расширенный диапазон преемственности. Развитие реальной науки требует проведения комплексных, качественных экспериментов и связано с обработкой большого количества результатов измерений. Измерения возможны через аналитически выделенные программные продукты PTC Mathcad, SciPy, Maxima, Xcos и соответствующие методы анализа накопленных данных. Проведение какого-либо эксперимента является частью задачи моделирования, ставящей целью использование построенной модели для практического применения (выполнения расчетов различных устройств, установок) или для дальнейшего развития теории и практики в технологиях обогащения янтаря. Для аппроксимации экспериментальных данных был проведен обзор и анализ существующих подходов, моделей, методов аппроксимации; обоснован выбор применяемого метода, выбран способ реализации программной системы для выполнения аппроксимации; проведена оценка достоверности полученных моделей методом анализа (корреляционного и регрессионного), а также сопоставлена сходимость данных моделей с результатами лабораторных, полупромышленных и промышленных испытаний. В исследовании была рассмотрена совокупность модели, метода, программного средства, которые адекватно отражают опытные данные и могут быть использованы для практического применения на различных этапах обогащения янтаря. При отсутствии опыта зарубежных и отечественных предприятий, который возможно было бы использовать при разработке и совершенствовании технологии обогащения янтаря, применение специальных методов обогащения является актуальным и перспективным направлением.
Для цитирования: Перепелкин М.А., Курбатова В.В., Склянов В.И, Тютюнин В.В., Козлов М.В. Аппроксимация и преемственная интеграция экспериментальных данных обогащения янтаря. Горная промышленность. 2019;(6):121-124. DOI: 10.30686/1609-9192-2020-2-121-124.
Информацияостатье
Поступила в редакцию: 19.04.2020
Поступила после рецензирования: 26.04.2020
Принята к публикации: 04.05.2020
Информацияобавторах
Перепелкин Михаил Александрович – кандидат технических наук, доцент кафедры автомобильного транспорта, доцент кафедры горного дела, ФГБОУ ВО Северо-Восточный государственный университет, г. Магадан, Российская Федерация; e-mail: Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Курбатова Вероника Владимировна – кандидат технических наук, доцент кафедры горного дела, ФГБОУ ВО Северо-Восточный государственный университет, г. Магадан, Российская Федерация; e-mail: Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Склянов Владимир Иванович – кандидат технических наук, заведующий кафедрой разработки месторождений полезных ископаемых, ФГБОУ ВО Норильский государственный индустриальный институт, г. Норильск, Российская Федерация; e-mail: Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Тютюнин Веденей Викторович – кандидат технических наук, директор, ООО «Инжи Инжиниринг», г. Иркутск, Российская Федерация; e-mail: Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Козлов Михаил Владимирович – руководитель службы по развитию и строительству, АО «Калининградский янтарный комбинат», п. Янтарный, Калининградская область, Российская Федерация; e-mail: Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript.
Введение
В настоящее время уровень развития технологий сортировки янтаря требует комплексного анализа существующих методов и средств с фокусировкой на расширенный диапазон преемственности.
Развитие реальной науки требует (подразумевает) проведения комплексных, качественных экспериментов и связано с обработкой большого количества результатов измерений, которые возможны через аналитически выделенные программные продукты PTC Mathcad, SciPy, Maxima, Xcos...
и соответствующие методы анализа накопленных данных. Под аппроксимацией понимается замена одних объектов другими, в том или ином смысле близких к исходным [1]. Применительно к проблеме с которой столкнулся АО «Калининградский янтарный комбинат», сортировка янтаря в настоящее время выполняется вручную, выглядит это так: сортировщица берёт в руки камень, взвешивает его, сравнивает с «эталонной коллекцией» и определяет в один из классов по цвету и качеству. При этом необходимо учесть, что цифровых критериев для определения классов не существует, и конечным потребителем продукции комбината является человек.
Проведение какого-либо эксперимента является частью задачи моделирования, ставящей целью использование построенной модели для практического применения (выполнения расчетов различных устройств, установок) или для дальнейшего развития теории и практики в технологиях обогащения янтаря.
Применительно к модернизации существующих промышленных объектов обогащения янтаря и проектированию новых, аппроксимация также применяется при типовом проектировании и разработке стандартных технологий переработки янтарьсодержащих песков.
Постановказадачи
Для аппроксимации экспериментальных данных необходимо выделить совокупность модели, метода, программного средства, которые адекватно отражают опытные данные и могут быть использованы для практического применения на различных этапах расчета, моделирования или проектирования различных объектов; провести обзор и анализ существующих подходов, моделей, методов аппроксимации; обосновать выбор применяемого метода; выбрать способ реализации программной системы для выполнения аппроксимации; оценить достоверность полученных моделей методом анализа (корреляционного и регрессионного), сопоставить сходимость данных моделей с результатами лабораторных, полупромышленных и промышленных испытаний. Эти действия необходимо будет проделать отдельно для ручной и машинной сортировки, сопоставить данные, выявить отличия и добиться того, чтобы шкала аппроксимации для разных видов сортировки была одинакова.
Аппроксимациявконцепциидобычиданных
Сложившаяся на основе практического применения разнообразных методов концепция добычи данных (ДД) (Data Mining) [2] объединяет методы по извлечению знаний из экспериментальных данных. При этом концепция ДД включает в себя использование не только совокупности математических методов, но и определенного инструментария (например, баз данных [3]), так как применение математических методов для обработки огромных накопленных массивов данных (называемых также хранилищами данных – warehouse) без средств вычислительной техники не представляется возможным.
Аппроксимация в концепции ДД возможна при отсутствии или лишь частичном знании законов (физических и химических), которым подчиняется исследуемый процесс обогащения. А как любой процесс – это достаточно большой объем данных.
Очевидно, что для анализа большого объема экспериментальных данных и последующей аппроксимации необходимо применить один из двух подходов [4, 5]:
Подход, опирающийся на существующую теоретическую базу (Theory-Driven), которая привязана в нашем случае к области техники обогащения.
В этом случае для решения задач аппроксимации достаточно применения методов регрессионного анализа (полиномиальная аппроксимация, экспоненциально-степенная аппроксимация, гармонический анализ и т. д.), что согласуется с этапами математического моделирования [6, 7].
Это означает, что в результате аппроксимации выполняется обобщение накопленных данных (опыта) и получение аппроксимирующей зависимости. В таких случаях задача аппроксимации данных – получение функциональной зависимости для вычисления коэффициентов уравнения, характеризующих исследуемый процесс обогащения. Полученные коэффициенты затем используем для интеграции к конкретным условиям.
Подход, основанный на извлечении информации из собранных экспериментальных данных (Data-Driven), теория в этом случае по большей части отсутствует или является неполной. Данный подход также может применяться для выявления в теории возможных противоречий с экспериментальными данными. При этом не выдвигаются предположения о законах, которым подчиняется анализируемый процесс, а используется исключительно информация, содержащаяся в имеющихся данных [8, 9].
При решении задач аппроксимации возможно различное применение генетических алгоритмов [10–12], в нашем случае видится – построение модели протекающего процесса. При этом планируется использовать метод группового учета аргументов – МГУА.
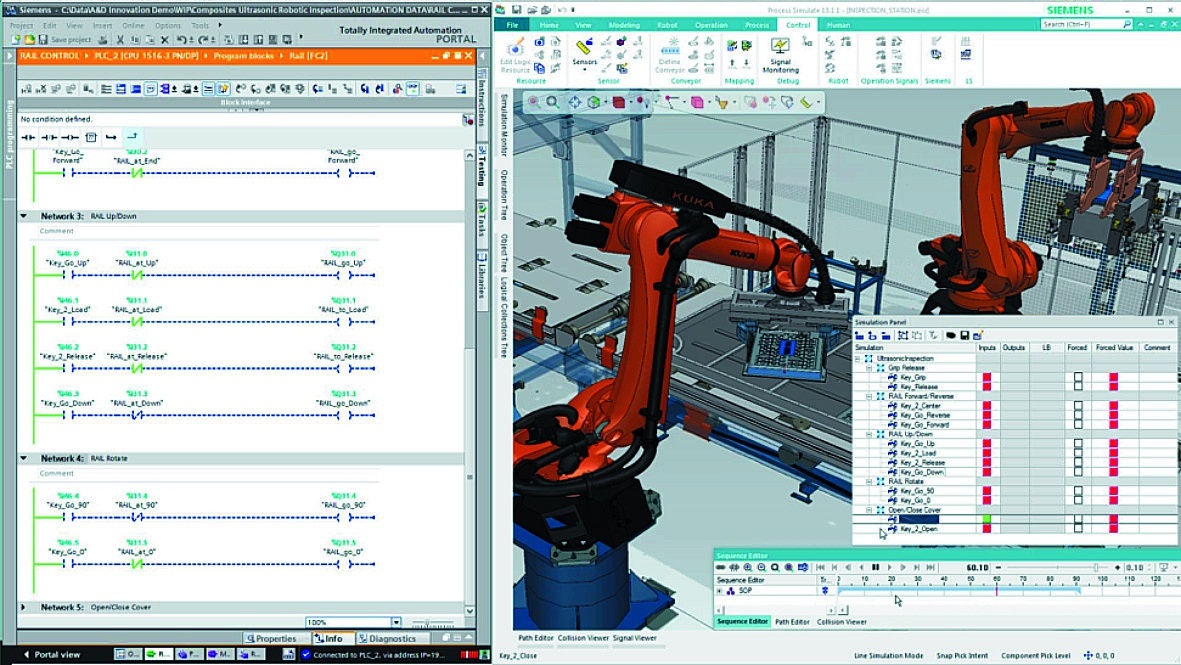
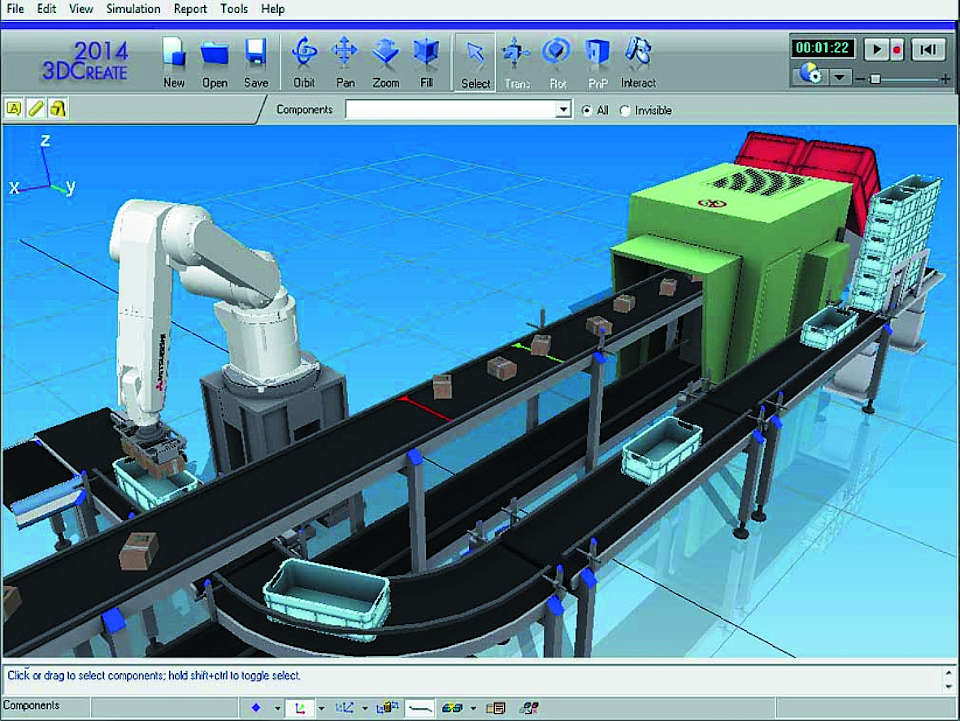
МГУА первоначально разделяет цели моделирования на две группы: для выяснения сущности объекта исследований или для решения динамических задач, учитывающих фактор времени и связанных с процессами или временными последовательностями. Это идеально интегрируется под наши задачи, для решения которых стоит рассмотреть не только метод, но и пространство его реализации с моделированием взаимоувязанных процессов, как вариант Tecnomatix – Siemens – для создания комплексного цифрового близнеца производства, основанного на симуляции, благодаря своей способности сочетать программное обеспечение, аппаратное обеспечение, технологии и производственные ноу-хау в портфеле цифровых производственных решений, включая моделирование установок и моделирование процессов (рис. 1), или CIMCO Setting up a 4th axis machine (рис. 2).
Рис. 1 Симулятор цифрового близнеца производства «Tecnomatix»
Fig. 1 Tecnomatrix simulation of a digital production twin
Рис. 1 Симулятор производства (линии) в среде CIMCO Setting up a 4th axis machineFig. 1 Production (line) simulation in CIMCO Setting up a 4th axis machine
Объектом обогащения при извлечении янтаря является «голубая земля» – глауконито-слюдисто-кварцевые пески с прослоями янтареносного алеврита и тёмных глин. Благодаря глаукониту содержащая янтарь порода имеет тёмно-зелёную, серовато- или голубовато-зелёную окраску, отчего и называется голубой землёй (особенно заметно отливает она голубизной на солнце) [13].
Так называемая «голубая земля» отличается плохой сортированностью. По данным проведенных исследований (Каплан), отмечается высокий коэффициент вариации гранулометрического состава – 1,442.
Выделение технологических типов сырья, их отдельная добыча и переработка нецелесообразны из-за опасности разрушения янтаря при перегрузках.
Плотность янтаря за редким исключением находится в пределах от 1,05 до 1,09 г/ см3. Янтарь тонет в пресной воде и всплывает в концентрированном растворе поваренной соли. При трении электризуется. Образования представляют собой округлые куски, капли правильной и реформированной формы, округлые лепешки, различные натечные формы.
Единственным в России предприятием, ведущим разработку Приморского месторождения янтаря, является АО «Калининградский янтарный комбинат». Разработка месторождения ведется с применением гидромониторов и гидротранспортной схемы транспортирования продуктов.
Отвальными продуктами являются отходы крупнее 50 мм из гидроклассификатора, не содержащие янтаря, и хвосты обогащения в виде суспензии, состоящие в основном из отходов класса –2 мм и хвостов +2 мм, содержащие гальку, желваки фосфоритов и неразмытые глиняные окатыши.
Процесс обогащения янтаря состоит в дезинтеграции «голубой земли», в отделении случайных валунов и содержащихся в перерабатываемой пульпе в небольших количествах гравия, фосфоритовых желваков и посторонних включений: щепы, растительных остатков, а также выделения янтаря из пульпы гравитационным методом (обогащением в суспензии плотностью 1,12–1,15 г/см3).
Обогащение янтаря включает в себя процесс дезинтеграции, ручной сортировки (улавливание классов +23 мм), многостадиальное грохочение (с выделением классов +2 мм) с последующей тяжелосредной сепарацией раздельных классов (перечистка).
Основными разделительными признаками янтаря являются: плотность (1,05–1,09 г/см3); крупность (промышленные классы +23 мм; –23+2 мм.); цвет и блеск; способность к электризации; люминесценция.
Издревле, в технологии обогащения янтаря преимущественно использовалось разделение по плотности в солёной воде, в которой янтарь всплывает, и ручная сортировка. Что касается непосредственно обогащения, то высокая контрастность янтаря на фоне вмещающих пород делает процесс обогащения простым и легко механизируемым, в то время как механизация сортировки янтаря долгое время считалась невозможной, так как фактически нужно было «заставить понять машину», красивый это камень (с человеческой точки зрения) или нет. Дальнейшее развитие методов сортировки янтаря безусловно должно быть совмещено с глубоким анализом накопленного эмпирического опыта переработки, а также применения свойств, которые ранее не применялись для промышленной сортировки янтаря. Особенно перспективными являются специальные методы сортировки, основанные на механизированной сортировке промытой руды с использованием нескольких свойств янтаря, а не какого-то одного свойства минерала.
Работа таких комплексов прежде всего основана на четких программных алгоритмах, базирующихся на корректных моделях сепарации.
Выводы
Рассмотрена совокупность модели, метода, программного средства, которые адекватно отражают опытные данные и могут быть использованы для практического применения на различных этапах обогащения янтаря. Также необходимо отметить, что ввиду отсутствия опыта зарубежных и отечественных предприятий, который возможно было бы использовать при разработке и совершенствовании технологии обогащения янтаря, применение специальных методов обогащения, несомненно, является актуальным и перспективным направлением.
Списоклитературы
1. Прохоров Ю.В. (ред.) Математический энциклопедический словарь. М.: Большая российская энциклопедия; 1995.
2. Mueller J., Lemke F. Self-organising Data Mining. An Intellegent Approach To Extract Knowledge From Data. Berlin: Dresden; 1999.
3. Корнеев В.В., Гареев А.Ф., Васютин С.В., Райх В.В. Базы данных. Интеллектуальная обработка информации. М.: Нолидж; 2000. Режим доступа: http://bookre.org/reader?file=608744.
4. Гайдышев И. Анализ и обработка данных: специальный справочник. СПб.: Питер; 2001. Режим доступа: http://bookre.org/ reader?file=496386.
5. Хемминг Р.В. Численные методы для научных работников и инженеров. М.: Наука; 1972. Режим доступа: http://bookre.org/ reader?file=556653.
6. Назаров А.В., Лоскутов А.И. Нейросетевые алгоритмы прогнозирования и оптимизации систем. СПб.: Наука и техника; 2003.
7. Осовский С. Нейронные сети для обработки информации. М.: Финансы и статистика; 2002. Режим доступа: http://bookre.org/ reader?file=555814.
8. Holland J.N. Adaptation in Natural and Artificial Systems. Ann Arbor, Michigan: Univ. of Michigan Press; 1975.
9. Ивахненко А.Г. Индуктивный метод самоорганизации моделей сложных систем. Киев: Наукова думка; 1981. Режим доступа: http://bookre.org/reader?file=343156.
10. Marenbach P. Using prior knowledge and obtaining process insight in data based modelling of bioprocesses. System Analysis Modelling Simulation. 1998;31(1–2):39–59.
11. Шуршев В.Ф., Умеров А.Н., Квятковская И.Ю. Аппроксимация экспериментальных данных по кипению озонобезопасных смесей хладагентов на основе генетических алгоритмов. В: Информационные технологии в образовании, технике и медицине: материалы Междунар. конф., Волгоград, 18–22 октября 2004 г. Волгоград: ВолгГТУ; 2004. Т. 2. С. 313–314.
12. Умеров А.Н., Шуршев В.Ф. Методы и программные средства аппроксимации экспериментальных данных. Вестник Астраханского государственного технического университета. 2005;(1):97–104. Режим доступа: https://elibrary.ru/item.asp?id=9956715.
13. Трофимов В.С. Янтарные россыпи и их происхождение. В: Смирнов В.И. (ред.) Геология россыпей. М.: Наука; 1965. С. 77–97.